re 모듈은 정규식 표현을 사용할 수 있다. 리스트로 태그를 나열하면 해당 태그들을 검색한다. lambda 함수를 정의해서 태그 속성이 2개인 경우만 정의한다. 태그 중에 align 속성이 center인 경우만 검색한다. 태그의 id 속성이 para로 끝나는 경우만 검색한다. HTML 속성을 생성해서 Class 속성만 검색한다.
HTML 태그로 검색에 용이한 객체 만들기
from bs4 import BeautifulSoup
doc = ['<html><head><title>Page title</title></head>', \
'<body><p id="firstpara" align="center">This is paragraph <b>one</b></p>', \
'<p id="secondpara" align="blah">This is a paragraph <b>two</b></p>', '</html>']
soup = BeautifulSoup(''.join(doc), 'html.parser')
#태그를 정렬해서 보여주기
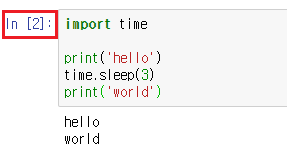
print(soup.prettify())
doc 참조 변수에 리스트 형태로 HTML 태그를 담았다. 검색이 용이한 soup 객체를 만들고 생성자인 join 메소드를 사용한다. 이 메소드는 리스트를 받으면 문자열로 리턴한다. 그리고 prettify 메소드를 사용하면 태그 정렬이 된다.
결과를 보면 HTML 태그가 들여쓰기 및 내어쓰기가 되어 출력된 것을 확인할 수 있다. <p> 태그 안에는 align이나 id 속성을 가지고 있는 것을 확인할 수 있다.
re 모듈 활용
from bs4 import BeautifulSoup
import re
doc = ['<html><head><title>Page title</title></head>', \
'<body><p id="firstpara" align="center">This is paragraph <b>one</b></p>', \
'<p id="secondpara" align="blah">This is a paragraph <b>two</b></p>', '</html>']
soup = BeautifulSoup(''.join(doc), 'html.parser')
#문자열 패턴을 손쉽게 정의할 수 있는 정규표현식 패턴을
#사용할 수 있는 re
tagsStartingWithB = soup.findAll(re.compile('^b'))
print([tag.name for tag in tagsStartingWithB])
re는 regular expression의 약자이다. 파이썬에 내장되어 있는 모듈이다. 정규 표현식 패턴을 정의할 수 있는 모듈이다. findAll은 전체를 다 검색해서 리스트로 리턴한다. re 모듈의 compile 함수를 써서 b라고 하는 어떤 형태로 시작하는 모든 태그를 의미한다. 파이썬의 리스트 내장 문법을 사용하여 for in문을 사용해서 리스트의 이름을 출력한다. 결과를 보면 <b> 태그가 올라온 것을 확인할 수 있다.
리스트를 나열하여 검색하기
from bs4 import BeautifulSoup
import re
doc = ['<html><head><title>Page title</title></head>', \
'<body><p id="firstpara" align="center">This is paragraph <b>one</b></p>', \
'<p id="secondpara" align="blah">This is a paragraph <b>two</b></p>', '</html>']
soup = BeautifulSoup(''.join(doc), 'html.parser')
#리스트로 태그를 나열하면 해당 태그들을 검색합니다.
print(soup.find_all(['title', 'p']))
위의 예제 코드처럼 <title> 및 <p> 태그를 리스트에 넣고 find_all 함수를 사용하면 전부 출력 가능하다.
lambda() 함수 활용하기
from bs4 import BeautifulSoup
import re
doc = ['<html><head><title>Page title</title></head>', \
'<body><p id="firstpara" align="center">This is paragraph <b>one</b></p>', \
'<p id="secondpara" align="blah">This is a paragraph <b>two</b></p>', '</html>']
soup = BeautifulSoup(''.join(doc), 'html.parser')
#람다함수를 정의해서 태그의 속성들이 2개인 경우만 검색합니다.
print(soup.find_all(lambda tag:len(tag.attrs) == 2))
파이썬에는 lambda() 함수 문법이 있다. 1회성 함수를 정의할 수 있는 문법이다. soup 객체가 갖고 있는 내부 데이터를 입력 데이터인 tag로 받는다. attrs가 2로 지정된 것은 속성이 2개가 있는 것만 함수를 정의하여 한 번 가져온다.
결과를 보면 <p> 태그만 aling 및 id의 속성으로 인해 2개의 결과가 나온 것을 확인할 수 있다.
re 모듈에 compile 함수를 이용하여 특정 패턴으로 끝나는 결과 찾기
from bs4 import BeautifulSoup
import re
doc = ['<html><head><title>Page title</title></head>', \
'<body><p id="firstpara" align="center">This is paragraph <b>one</b></p>', \
'<p id="secondpara" align="blah">This is a paragraph <b>two</b></p>', '</html>']
soup = BeautifulSoup(''.join(doc), 'html.parser')
#태그의 id속성이 para로 끝나는 경우만 검색합니다.
print(soup.find_all(id=re.compile("para$")))
예제 코드와 같이 re 모듈의 compile 함수를 사용하여 para$를 쓰면 para로 끝나는 패턴을 찾는다. 출력 결과의 id 속성을 보면 para로 끝나는 형태만 출력된 것을 확인할 수 있다.
특정 스타일을 지정하여 검색하는 방법
# #다시 간단한 HTML소스를 생성해서 class속성을 통해 검색합니다.
soup =BeautifulSoup("""
Bob's<b>Bold</b>Barbeque Sauce now available
<b class="hickory">Hickory</b> and <b class="lime">Lime</a>
""", "html.parser")
# #<b>태그 중에 class=lime이라고 되어 있는 태그를 검색합니다.
print(soup.find("b", {"class":"lime"}))
#태그중에 align속성이 "center"인 경우만 검색합니다.
# print(soup.find_all(align="center"))
<b> 태그 중에 class 속성이 lime으로 지정되어 있는 태그만 검색한다.
find() 함수를 이용하여 간단하게 원하는 콘텐츠만 검색해보기
# #다시 간단한 HTML소스를 생성해서 class속성을 통해 검색합니다.
soup =BeautifulSoup("""
Bob's<b>Bold</b>Barbeque Sauce now available
<b class="hickory">Hickory</b> and <b class="lime">Lime</a>
""", "html.parser")
# #<b>태그 중에 class=lime이라고 되어 있는 태그를 검색합니다.
print(soup.find("b", {"class":"lime"}).get_text())
get_text 함수를 사용하면 앞 뒤에 있는 태그를 없애고 원하는 컨텐츠(문자열)만 검색 가능하다.
결론
파이썬에 내장되어 있는 re 모듈을 BeautifulSoup과 같이 사용하면 보다 강력한 검색이 가능하다.