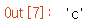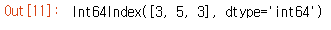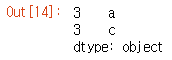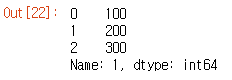인터넷 상에서 데이터 활용 방법
인터넷 상에는 수많은 데이터 정보가 있다. 그리고 공개된 데이터들 중에서 아래와 같이 다양한 형식들을 읽어볼 수 있다.
- URL 상의 CSV
- CSV 파일을 local에 다운로드 받은 후에 pandas.read_csv(url)를 사용하여 읽어볼 수 있다. 또는 URL을 알고 있다면 지정해서 바로 넘겨줄 수도 있다.
- 크롤링을 사용하여 읽기
- 가공되지 않은 데이터를 처리할 때는 크롤링을 사용해야 한다.
- 파이썬의 requests/Selenium 라이브러리를 통해 처리한다.
- pandas.read_html(url, ...)
- 사이트에 따라 URL을 제공하는 경우 내부적으로 requests 라이브러리 활용하여 특정 웹 페이지의 dataframe을 반환받을 수 있다.
- pandas-datareader 라이브러리(0.7.0 버전 기준)
- 내부적으로 requests 라이브러리 활용
- 지원 데이터 소스: FRED, Nasdaq, Yahoo Finance, Google Finance 등을 손쉽게 활용 가능하다. 하지만 정식 API가 아닌 크롤링을 사용하는 것이기에 버전에 따라 오류가 발생할 수 있다.
- seaborn 라이브러리
- 데이터 시각화를 도와주는 그래픽 차트 라이브러리, 예제용 데이터 제공
- https://github.com/mwaskom/seaborn-data
주식 종목코드(KOSPI, KOSDAQ) 가져오기
환경 설정을 위해 인터넷 상의 데이터를 가져와야 하므로, 한국 거래소(KRX)로 접속한다.
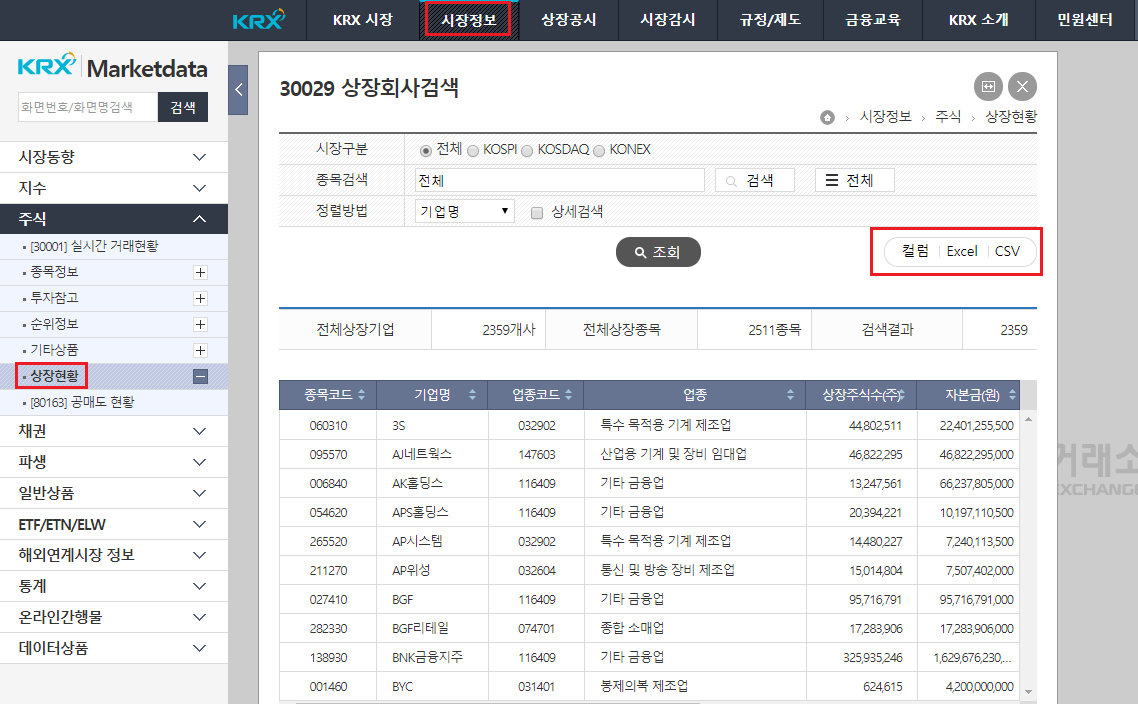
[시장정보] -> [상장현황] -> KOSPI 및 KOSDAQ을 클릭하여 조회 -> CSV 파일을 로컬 디렉터리에 저장한다.
pandas.read_csv 활용
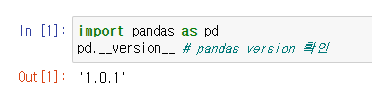
import pandas as pd
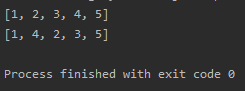
df = pd.read_csv('data/kospi.csv', error_bad_lines=False)
df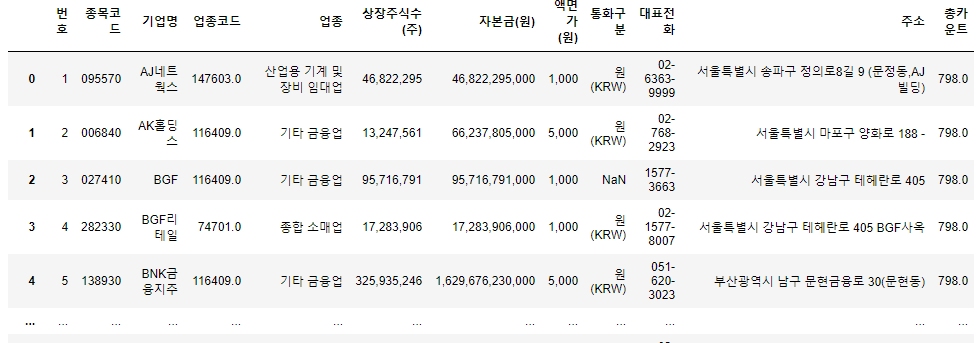
CSV 파일을 읽어보니 ParserError가 발생하여 'error_bad_lines=False'로 막아놨다. 위의 코드를 쥬피터 노트북에 넣으면 코스피에 상장된 기업명과 업종코드들을 차트로 확인할 수 있다.
import pandas as pd
df = pd.read_csv('data/kospi.csv', error_bad_lines=False)
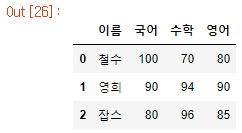
print(df.shape)
df.head()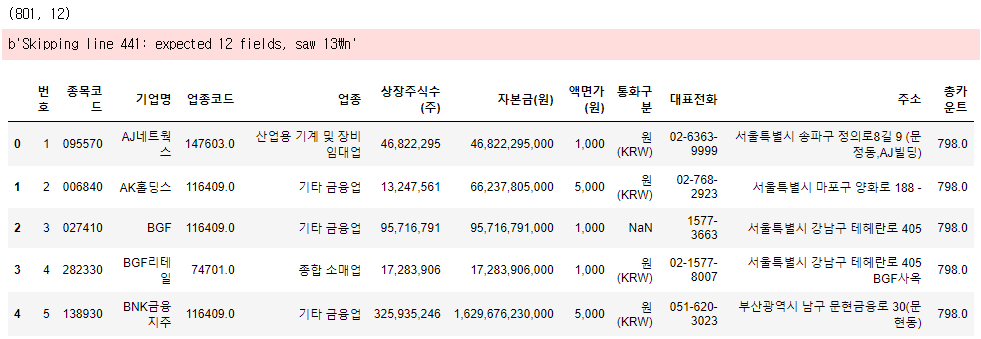
위의 예제 코드를 일반적인 Pandas의 Dataframe 활용 예제로 바꿔본 결과이다. 801행, 12열의 테이블임을 확인할 수 있고 'head'를 사용함으로써 상위 5개 행을 볼 수 있다.
import pandas as pd
df = pd.read_csv('data/kospi.csv', index_col='기업명',error_bad_lines=False)
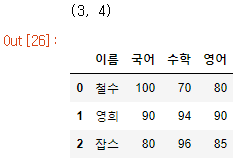
print(df.shape)
df.head()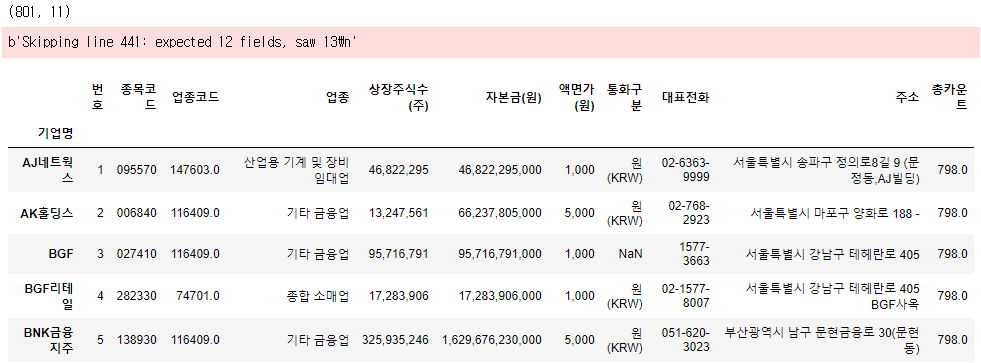
이전의 예제 코드에서는 행의 인덱스가 0부터 1까지 순차적인 일련번호로 구성되어 있었다. 이때 인덱스를 정의할 수 있는데 pd.read_csv를 사용할 때 'index_col'을 전달 인자로 넣으면 지정된 열이 기준이 되어 테이블이 표시된다.
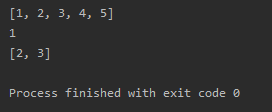
df.loc['AK홀딩스']
loc 인덱서를 활용하여 'AK홀딩스'를 출력한 결과이다. 종목코드, 업종코드, 업종 등 'AK홀딩스'와 관련된 정보들만 확인 가능하다. 이와 같이 pd.read_csv를 사용하여 코스피나 코스닥에 대한 원하는 기업명의 정보들을 효율적으로 손쉽게 검색 가능하다.
pandas.read_html
HTML 문자열로부터 문자열 내에 테이블 태그(Tag)가 있다면 태그 내용을 수집(parsing)해서 dataframe화 시켜준다.
- 웹페이지 크롤링을 쉽게 도와주는 라이브러리
- 위의 기능을 활용 불가능한 곳도 있기 때문에 만능은 아니다.
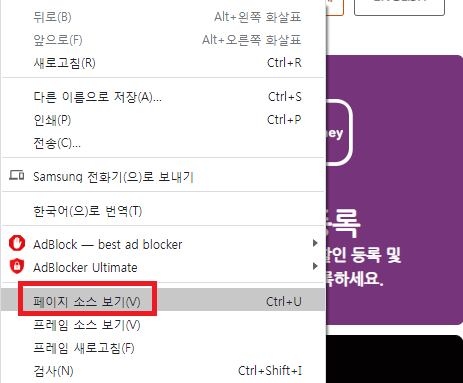
- 활용 가능 여부를 판단하기 위한 기준은 해당 페이지 상에서 우클릭 후 페이지 소스 보기를 통해 찾고자 하는 데이터에 대한 테이블 태그가 있는지 확인을 해야 한다.
- 하지만 해당 페이지에 DDoS(Distributed Denial of Service) mitigration이 적용되어 있을 경우 동작이 어렵다.
- 웹 페이지 상의 HTML 테이블을 한 번에 로딩하기 위한 목적이다.
- HTML 테이블에 데이터 외에 다른 문자열이 있을 경우에 곤란하다.
- 직접 크롤링하는 것이 간편하다.
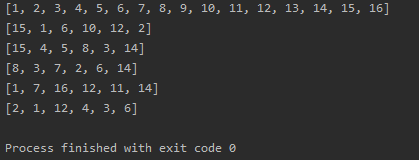
df = pd.read_html('https://astro.kasi.re.kr/life/pageView/5')
df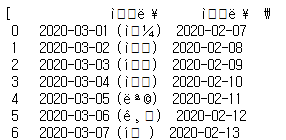
한국천문연구원 천문지식정보의 월별 음양력 웹 페이지를 import하여 하나의 Dataframe으로 읽는다. 그런데 결과를 보면 한글이 깨져서 이상한 출력 결과를 나타낸다. 한글이 깨진 부분이 인코딩 부분이기 때문에 올바른 출력을 위해서는 웹페이지 import 시에 인코딩 조건이 필요하다.
df_list = pd.read_html('https://astro.kasi.re.kr/life/pageView/5', encoding='utf-8')
df_list
import 인코딩 조건으로 'utf-8'을 전달 인자로 넣어주면 한글이 깨지지 않고 올바르게 출력된 것을 확인할 수 있다. 하지만 모양이 Dataframe 형태가 아니다. 그 이유는 리스트 안에 Dataframe이 포함되었기 때문이다. 위와 같이 리스트 안에 포함된 이유는 웹 페이지 상에는 리스트 안에 여러 개의 Dataframe을 넣어 구성된 경우가 있을 수 있기 때문이다. 따라서 list가 반환되었다.
len(df_list)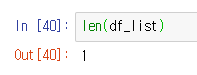
df = df_list[0]
print(df.shape)
df.head()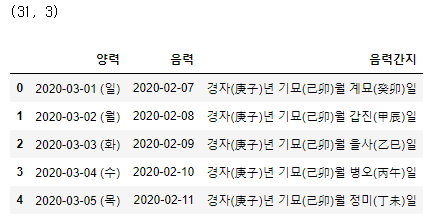
리스트의 길이를 구해보면 1이다. 따라서 리스트에 dataframe이 한 개 들어있다는 것을 확인할 수 있다. 리스트의 인덱스를 활용하여 0번 인덱스를 df 참조 변수에 넣고 출력해보면 dataframe 형태로 읽혀 지는 것을 손쉽게 확인 가능하다.
pandas-datareader
Pandas에 있는 별도의 third party 라이브러리이다. 이를 사용하기 위해서는 라이브러리를 설치해야 하며 이미 설치되어 있더라도 업데이트를 해주어야 한다. 그 이유는 위의 라이브러리는 버전 업데이트가 빠른 외부 API 및 외부 웹 페이지를 크롤링하기 때문이다.
- 최신 버전의 pandas-datareader 업데이트는 필수이다.
- 명령 프롬프트 또는 Windows PowerShell을 실행한다.
- pip install --upgrade pandas-datareader
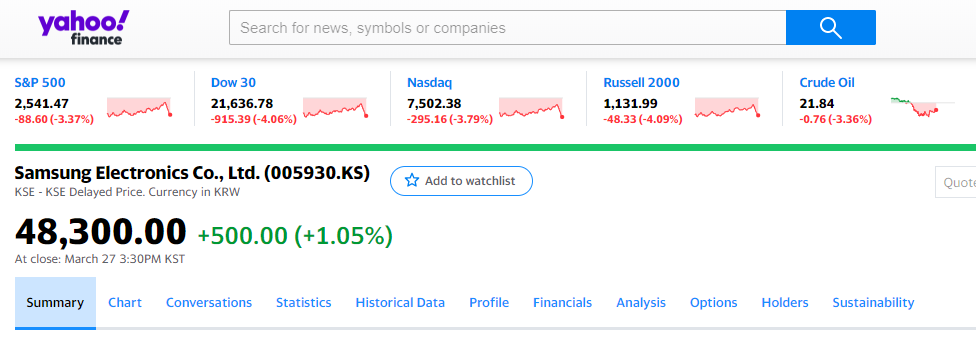
위의 라이브러리를 사용하기 전에 우선 활용할 데이터 종목을 알아본다. Yahoo finance를 사용하여 증권 정보를 가져올 것이고, 해당 정보는 Yahoo finance(https://finance.yahoo.com/)에서 확인 가능하다.
위의 사이트에서 볼 수 있듯이, 삼성전자의 종목 코드는 005930.KS임을 확인할 수 있다. 알아낸 증권 정보를 활용하여 위의 라이브러리를 사용한다.
import pandas_datareader as pdr
pdr.get_data_yahoo('005930.KS', '2020-03-01')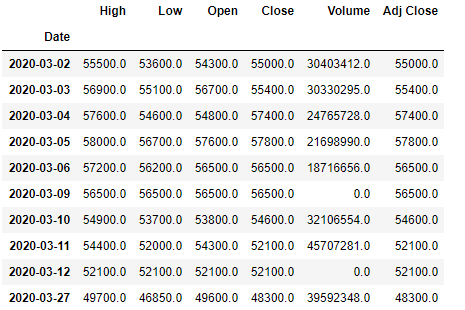
datareader를 통한 증권 정보를 import한다. 그리고 Yahoo finance에서 확인한 종목코드 및 검색하고 싶은 기간을 지정한다. 위의 출력 결과를 보면 2020-03-01은 휴일이라 데이터가 없는 것을 확인할 수 있고 주식 거래가 이루어진 날들의 데이터 수집 결과들을 손쉽게 얻어올 수 있다.
결론
Pandas를 사용하여 인터넷 상의 데이터를 손쉽게 수집할 수 있다. 하지만 '월별 음양력'과 같이 모든 데이터들을 수집하여 읽을 수 있는 것은 아니기 때문에 웹 페이지에 따른 고급 크롤링 기술이 필요할 수 있다.
'언어 > Python' 카테고리의 다른 글
| [Python] Python(파이썬) Pandas 소개 및 자료구조 (0) | 2020.07.27 |
|---|---|
| [Python] Jupyter Notebook(쥬피터 노트북) 활용 (0) | 2020.07.15 |
| [Python] Python(파이썬) 데이터 분석 환경 구축 (0) | 2020.07.10 |
| [Python] HTML 문서를 BeautifulSoup으로 검색하기 (0) | 2020.07.07 |
| [Python] 웹 크롤링의 이해와 BeautifulSoup 설치 (1) | 2020.07.05 |